ローカル環境で画像生成系AI-Fooocusを動かしてみた
最近のWeb広告ってAI美女多いよね~なんて友人と話していて、そういえば「自分で画像生成系AI触ったことないな?」と思い、やってみました。
今回使用したのは、Stable Diffusion(SDXL)をローカル環境で動作させることができるFooocusです。環境構築面倒くさいんだろうなーという事前の想定を覆すほどあっという間に美女を量産することができました。拍子抜けです。
動作させるまでの流れと、実際の出力結果をまとめました。使用期間は1日だけで、使い込むとはいきませんが、なんとなくわかってきたという感じです。
- 画像生成系AIに興味を持っていたけど、全く使ったことがなかった
- ローカル環境で動かしてみたかった(お試しなので課金したくなかった)
- PCスペックは中の上ぐらい?最新・最高のスペックではない
- NSFW(平たく言うと18禁のエロ)は興味がないので試していない
環境構築の話は後にして、最初に出力た画像を並べてみます。
「浴衣の日本人女性で、背景は花火にして」という指示で出てきたのがこちら。
なるほど、いきなりいわゆるAI美女が出力されるわけではないのね。と理解。


続いて「AI美女と言ったら水着でしょ!広告で見た!」ということで、「水着の日本人女性で、背景はプール」と指示して出てきたのがこちら。







途中でホラーな画像も出力されて、怖くなったので、一旦ストップ。
ちゃんと調べてみることにしました。
そういうわけで、話を環境構築まで話を戻します。
画像生成をするにあたって、お試しでも課金をしたくなかったので、ローカル環境で動くものを調査。画像生成系AIと一口に言っても種類があることがわかりました。モチベーションが続けばそれぞれの比較もしてみたいところです。
今回使用したのはStability AI社が提供しているStable Diffusion XL(以下、SDXL)を手軽に使えて、かつローカル環境でWebアプリとして使えるFooocusです。Lvmin Zhang氏のGithubで公開されています。

readmeに使い方が書いてあるのですが、要するにダウンロードして、解凍して、「run.bat」を動かせ!というだけの超お手軽。ありがたいですね。
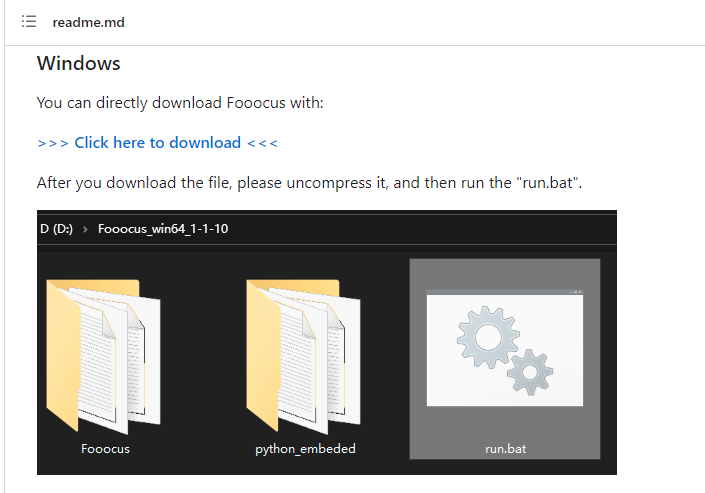
「run.bat」を叩くと、初回は学習モデル(Stable Diffusionでは、Checkpointsと呼ばれる)をダウンロードし始めます。6~7GBぐらいあり、なかなかの容量ですが、2回目以降はダウンロード不要です。たぶん、HDDに置くより、SSDに置いたほうが良いです。今後のためにもディスク容量には余裕をもちましょう。
ブラウザが立ち上がって、こんな画面がでてきます。
アドレスは「http://127.0.0.1:7861/」で、ローカル環境です。
あとは、「Type prompt here.」と書いてあるテキストボックスに、命令文(プロンプト、いわゆる「呪文」)を入力して、「Generate」ボタンをクリック。しばらくすれば画像が出力されます。
出力先は、「Fooocus\outputs」で、勝手に日付ごとのフォルダが生成されます。
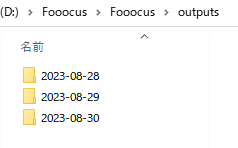
わかりやすくて、とても簡単。
「 Advanced 」にチェックを入れると、右にメニューが出現します。
左から順に、Setting / Style / Advanced 。
Settingタブ
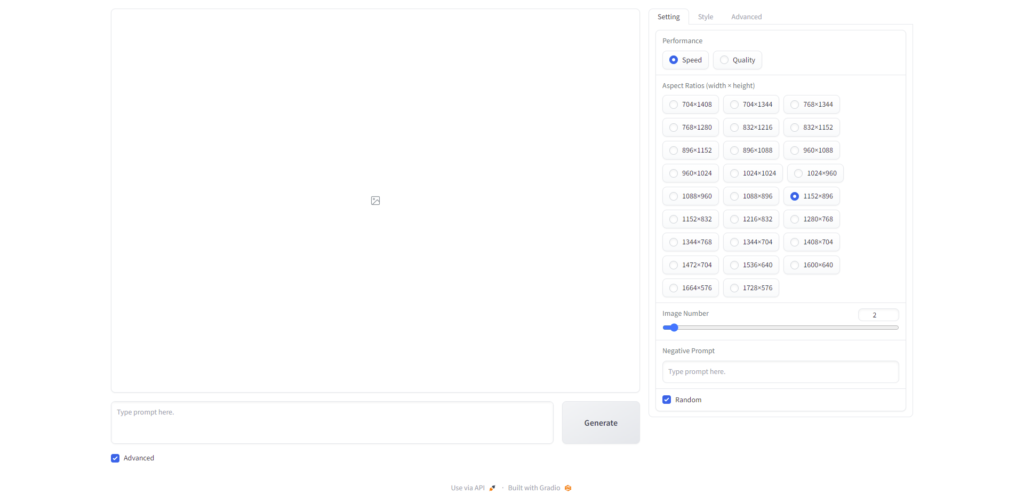
画像の出力に関するパフォーマンス設定「Speed」または「Quality」や、画像サイズ、出力枚数を指定します。
「Negative Prompt」は除外したい指示を出力します。AI特有の謎の文字や、変な指の形が出力されたりするので、そういったものを除外する使い方のようです。
「Random」について少し複雑なので、ざっくり噛み砕いて説明します。AIはランダムに出力しますが、ランダムと言っても内部的にはSeed値を持っていて、そのSeed値が近いと似た出力がされます。
美女の出力で例えると、「9000というSeed値の美女はタイプだけど、5000はタイプじゃないな・・・」というときに、予め9000というSeed値を与えておけば、好みの美女を出力し放題!というわけです。また、隣接するSeed値では、近い出力が得られるということで、8999や9001では好みの美女になりやすい、ということになります。(もちろんそう上手くはいかず、苦労します。)
Styleタブ
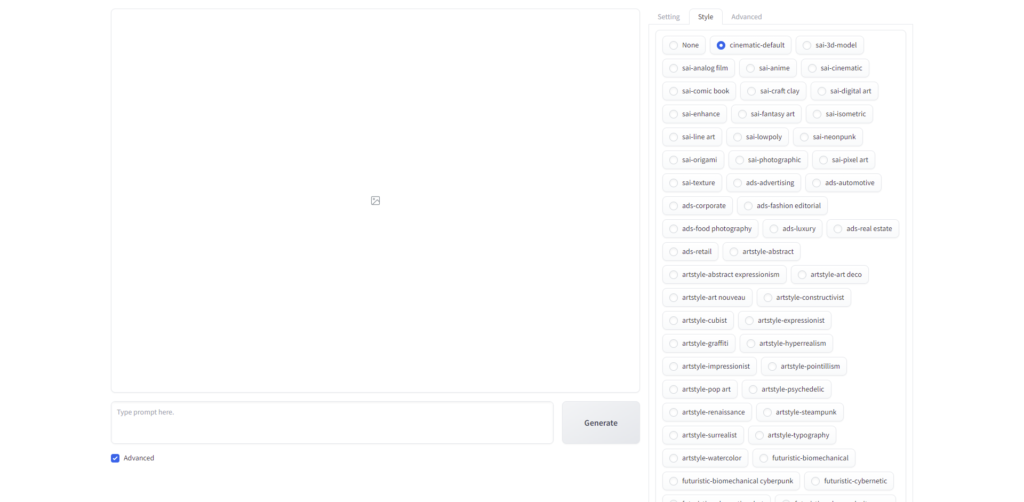
たくさんの種類があるので、超簡単にいうと、出力する画像の雰囲気設定です。リアル調とか、漫画とか、3Dアートとか、SFチックとか、ドット絵とか。
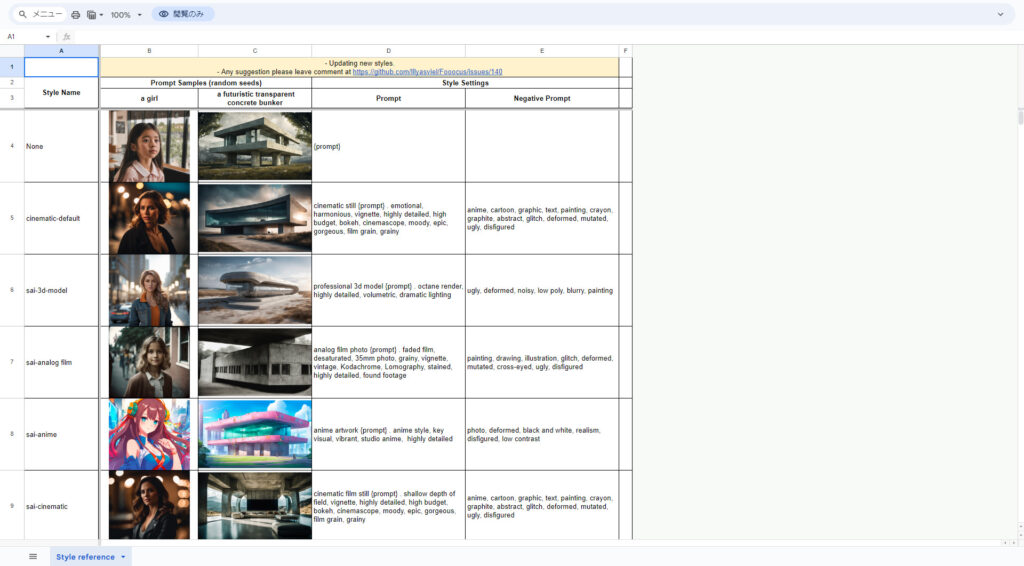
何を選べば、どういう出力になるのかというのは、Googleスプレッドシートにまとめられていまして、実にわかりやすいです。
Advancedタブ
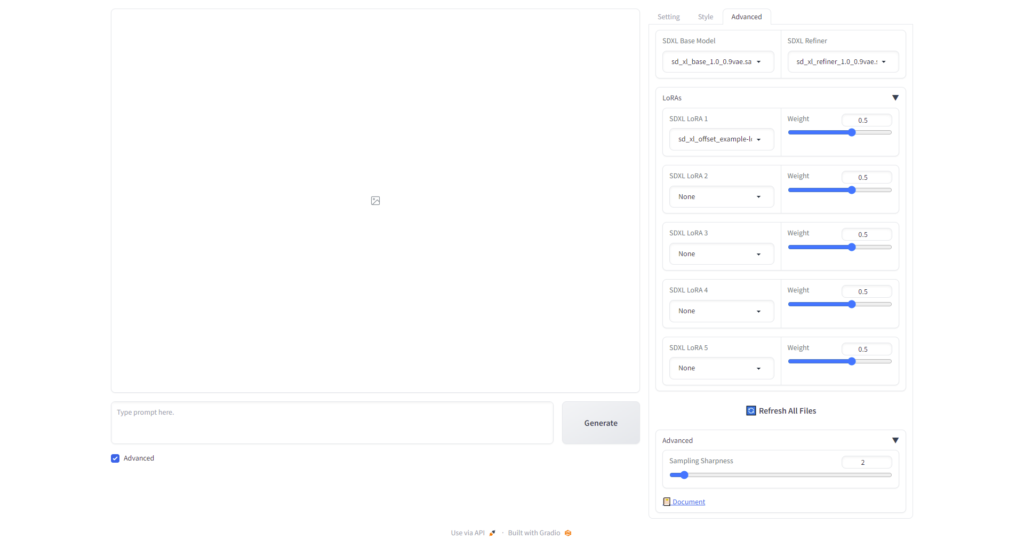
Stable Diffusionは、ベースとなる学習モデル(Checkpoints)の他に、追加学習モデル(LoRA、Low-Rank Adaptation)を足すことで、出力のコントロールができます。
Fooocusをデフォルト状態で使用すると、どことなく怖い画像が出力されたのはこの影響でして、美女やアニメ絵、SFなどなど、ジャンル毎の学習モデルを使用することで、特化した出力ができるということです。
Checkpointsも、LoRAも、有志が公開していまして、有名なサイトは「Civitai」というもの。軽く眺めるだけで、「あーネットでよく見る美女だ!」と思うようなモデルが公開されています。
超ざっくりまとめると、ネット上からダウンロード(もしくは自分で作った)学習モデルを指定するのが、「Advanceタブ」というわけです。
今回のお試しにあたって、Checkpointは「XXMix_9realisticSDXL – Test_v2.0」を使用しました。
また、LoRAは「Japanese Girl – SDXL – v1.1」を使用しました。















ホラーな出力がされたときにはどうなることかと思いましたが、公開されている学習モデルを使用することで、無事にかつ簡単に美女画像を量産できました。完全に理解した。
使用上の注意点や、試した指示(prompt)、モデルの重み付け等々については、また別の記事にまとめます。